




I. Introduction▲
À l'ère des Big Data, c'est la grande agitation dans les entreprises. Ces dernières n'ont jamais fait face à une quantité de données aussi importante. Plusieurs départements à savoir le marketing, la communication, les opérations, etc. s'intéressent à l'exploitation des données afin d'en extraire des business-values. En d'autres termes, il s'agit de l'information pertinente pour faire grandir le business de l'entreprise. Cette business-value est fonction du département et ne sera pas la même selon qu'on est dans le département x ou y.
Pour répondre à ce besoin d'exploitation de données massives, il s'avère que l'écosystème Hadoop serait la solution open source par excellence. Les raisons sont multiples : la communauté grandissante autour de cette technologie, l'implication des grandes firmes par la multiplication des distributions et sans oublier toute la propagande médiatique et je passe.
Je ne fais aucunement la publicité de la solution Hadoop, je relève juste des faits en partageant mon expérience, j'espère que vous comprenez ce que je veux dire . Cet article présente comment installer un cluster Hadoop à un nœud, l'intégration de Hadoop et Eclipse et les potentielles erreurs auxquelles peuvent être confrontés les débutants et enfin les techniques pour y faire face.
En règle générale, nous le verrons plus loin dans cet article, le framework Hadoop peut être déployé de trois façons en local mode, en mode pseudodistribué et en mode distribué complet. Nous avons choisi dans le cadre de cet article d'utiliser Hadoop sur un nœud pour les raisons suivantes qui sont plus ou moins pertinentes en fonction du besoin à couvrir :
- la mise en place d'un Proof Of Concept pour montrer que la solution que nous voulons développer est faisable. Dans la plupart des cas, pour montrer cela, on simule un environnement pour montrer la faisabilité. La simulation avec un nœud nous a suffi pour mettre en place notre POCProof Of Concept ;
- les moyens financiers mis à notre disposition ne nous permettaient pas d'acquérir plusieurs machines afin de créer un réel cluster avec des nœuds distincts.
Lançons-nous dans cet univers qui sans doute nous réserve de belles surprises. Le voyage risque d'être très long, avez-vous pris votre tasse de café ?
II. Contexte▲
Cet article a été réalisé à la suite d'une étude et d'une analyse autour d'un sujet qui m'a été confié et qui était intitulé : je paraphrase, les bénéfices du Big Data et de la gestion centralisée des logs pour la détection de fraudes.
Cette étude a été menée dans une institution financière francilienne. Je m'abstiens de donner le nom pour des raisons de « non-publicité » et également de « sécurité ». L'étude que j'ai menée consistait :
- premièrement à étudier les solutions du marché en termes de gestion centralisée des logs (identification des logs, collecte des logs, standardisation des logs, analyse et indexation des logs et enfin corrélation des logs) pour répondre à un besoin business : l'optimisation de la détection de fraudes ;
- deuxièmement, proposer un modèle de mise en place de contrôles de sécurité en utilisant le modèle de conception et de programmation MapReduce.
Je ne fais pas un cours magistral sur la gestion centralisée des logs ou encore moins une mise en exergue de mes prouesses, loin de là. Bien que je n'hésiterai pas si l'occasion m'était offerte. Je n'irai pas plus loin. Pour ceux que cela intéresse, nous pouvons échanger et partager en off.
III. Prérequis pour la réalisation de ce tutoriel▲
Un ensemble de prérequis ont été nécessaires à la réalisation de ce tutoriel. Ils sont de plusieurs ordres :
- les connaissances théoriques nécessaires pour comprendre les notions abordées dans la suite de l'article telles qu'un cluster Hadoop, un NameNode, un DataNode, MapReduce, HDFSHadoop Distributed File System et autres. Car dans cet article, ces notions ne seront pas expliquées. Elles sont supposées être acquises. Le site internet http://hadoop.apache.org est suffisamment exhaustif sur ces notions et plus encore, un coup de chapeau à Mickael Baron qui a su donner un élan grâce à ces premiers articles. Les lire ici ;
- un ensemble de logiciels nécessaires pour la réalisation du tutoriel. Je vais énumérer tous les logiciels dans le paragraphe suivant ;
- une connaissance minimale en programmation, en Java, en Shell, en XMLeXtended Markup Language est également nécessaire pour comprendre les classes Java et le contenu des fichiers XML que nous allons écrire dans la suite.
III-A. Liste des outils et logiciels utilisés▲
Comme outils logiciels pour la réalisation de ce tutoriel, nous citerons :
- une machine virtuelle Linux RedHat. La distribution et la version utilisées sont données dans l'image suivante. Vous pouvez taper la commande suivante :
cat /etc/issue
Cependant, il faut noter que toute distribution Linux compatible GNU/Linux est supportée par la plateforme Hadoop ;
- le SSH est un protocole de communication sécurisé qui nous permet d'ouvrir un Shell sur une machine distante. Autrement dit, SSH permettra à son utilisateur de se connecter à distance sur une machine ou un serveur connaissant son adresse IP. Plus loin dans ce tutoriel, nous expliquerons comment le tester dans notre contexte.
L'utilitaire Putty est un client SSH. Il sera très important dans la mesure où il vous permettra de vous connecter à votre machine virtuelle depuis votre poste de travail. L'icône de Putty est donnée par l'image suivante :
- le service HTTPD doit être opérationnel sur la machine virtuelle. Il s'agit du service web qui puisse permettre de lancer une application web.
Pouvoir prendre la machine virtuelle à distance impose que le service SSHD soit opérationnel sur la machine virtuelle. Je peux reconnaitre que ce service fonctionne sur ma machine virtuelle en faisant la commande suivante :
ps -ef | grep -i sshdLe résultat sur ma machine virtuelle est le suivant :

- la version de Hadoop que nous utilisons est la stable release 1.2.1. Dans la suite de l'article, nous expliquerons comment l'acquérir et comment l'installer pour en profiter pleinement. Il s'agit d'une simple archive.
Hadoop 1.2.1 est la version la plus stable de Hadoop qui implémente les concepts de base de Hadoop à savoir le NameNode, le SecondaryNameNode, le DataNode, le JobTracker, le TaskTracker. Il existe cependant une version de Hadoop qui introduit d'autres concepts comme YARN (MapReduce en version 2), les RessourceManager, le NodeManager, mais ces derniers ne font pas l'objet de cet article ; - la version de Java à utiliser doit être au moins la JAVA 6, celle que j'ai utilisée pour la réalisation de ce tutoriel est donnée par la capture d'écran suivante :

Nous venons de lister les outils nécessaires à la réalisation de ce tutoriel. Lançons-nous dans la mise en œuvre proprement dite de notre cluster.
IV. Installation d'un cluster Hadoop à nœud unique▲
Je me suis inspiré de la documentation officielle de Hadoop (http://hadoop.apache.org/docs/r1.2.1/). J'ai aussi usé de mon expérience et des retours d'expérience des uns et des autres. Il en ressort le condensé suivant.
IV-A. Téléchargement de la version stable 1.2.1 de Hadoop▲
Le téléchargement de la version stable 1.2.1 de Hadoop est aussi simple que la copie d'un fichier. Vous pouvez suivre le lien suivant http://mirrors.koehn.com/apache/hadoop/common/ qui représente l'un des serveurs miroirs sur lesquels vous pouvez acquérir la version 1.2.1 de Hadoop. Toutefois, vous avez le choix de sélectionner un autre serveur.
IV-B. Création d'un utilisateur pour Hadoop▲
Pour faire les choses proprement, je vous recommande de créer un groupe d'utilisateurs « hadoop » et un utilisateur « hadoop » qui appartiendra à ce groupe. Ce dernier doit avoir tous les droits sur le répertoire /home/hadoop.
Vous avez une panoplie d'articles pour la création d'un groupe d'utilisateurs sous Linux. Celui-ci n'est pas mal : Les utilisateurs et leurs droits.
Pour changer d'utilisateur, dans mon contexte, j'ai utilisé la commande suivante. La capture d'écran en fait une illustration claire.
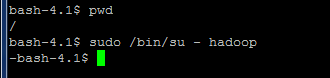
Dans mon cas, lorsque je créais l'utilisateur « hadoop », je n'ai pas pu faire une capture d'écran pour illustrer. Néanmoins, j'ai tout fait dans la suite avec l'utilisateur « hadoop » car il n'est pas aussi lourd qu'un éléphant jaune.

IV-C. Préparation de l'environnement▲
Une fois l'archive de Hadoop obtenue, il faut la copier dans le répertoire /home/hadoop et la décompresser. Une illustration en est faite avec l'image suivante.
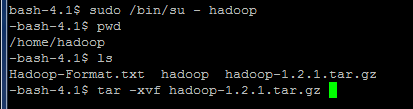
Tout d'abord, j'ai changé d'utilisateur pour passer à l'utilisateur « hadoop ». Ensuite, j'ai fait la commande ls pour m'assurer que mon archive est bien dans mon répertoire /home/hadoop. Enfin, j'ai fait la commande tar pour décompresser mon archive avec les options -v pour le mode verbeux, et -f pour dire que je vais préciser le fichier à décompresser.
IV-C-1. Mise à jour du fichier conf/hadoop-env.sh▲
Une fois que l'archive a été décompressée, le répertoire « hadoop » contenant tous les programmes nécessaires au fonctionnement de Hadoop est accessible. Nous devons informer Hadoop sur l'emplacement de Java sur notre machine virtuelle. Pour cela, nous devons modifier le fichier conf/hadoop-env.sh qui se trouve dans le répertoire « hadoop » issu de la décompression.
Nous faisons les commandes suivantes sur le prompt tel qu'illustré sur la capture d'écran suivante.

Après avoir exécuté les trois commandes suivantes :
2.
3.
pwd
cd hadoop
ls
on accède au contenu du répertoire « hadoop ». On remarque bel et bien l'existence du répertoire conf.
Pour modifier le fichier conf/hadoop-env.sh, je vais utiliser l'éditeur nano, pour éviter les ennuis avec l'éditeur vi qui est réservé aux experts (, je n'en suis pas un). L'image suivante en illustre la situation :

Vous devez ajouter la ligne concernant la configuration de la variable JAVA_HOME en fonction de la configuration de votre installation de Java. Pour mon cas, ma configuration est en encadré rouge. Voir capture d'écran.

La configuration de base étant prête, pour vous assurer que Hadoop est désormais fonctionnel sur votre machine virtuelle, il faut faire la commande suivante :
bin/hadoopVous devez voir apparaître un écran similaire au suivant :
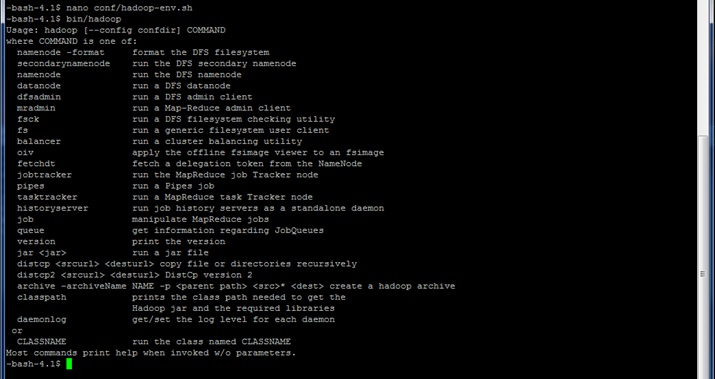
Eurêka, nous avons réussi.
Il faut noter que le démarrage d'un cluster Hadoop peut se faire de plusieurs façons :
- en mode local : c'est le mode basique, où il n'y a qu'un seul processus qui tourne pour Hadoop ;
- en mode pseudo distribué : ici, on simule un cluster réel en utilisant une seule machine. Dans ce contexte, plusieurs processus Java sont lancés sur la même machine (même machine virtuelle Java également) pour simuler les processus opérant dans le monde Hadoop à savoir un NameNode, un SecondaryNameNode, un DataNode, un JobTracker et un TaskTracker. Ce qu'il faut garder à l'esprit est que tous ces processus sont lancés sur la même machine, il faut donc prendre en compte les ressources de votre machine si vous souhaitez simuler ce modèle. C'est ce mode que j'ai utilisé dans la réalisation de cet article ;
- en mode entièrement distribué : c'est le mode réel de cluster où tous les nœuds sont indépendants les uns des autres. Chaque processus tourne sur une machine virtuelle Java différente.
L'objectif ici n'est pas de faire un cours magistral sur les concepts de Hadoop ou sur la distribution des charges (confer cours de physique électrostatique : 1re année. Just for fun). La littérature est assez exhaustive sur le sujet.
Pour exécuter les processus Hadoop (autrement dit, démarrer notre cluster Hadoop) en mode pseudodistribué, nous devons encore faire des configurations supplémentaires. En s'inspirant de la configuration faite dans le fichier conf/hadoop-env.sh précédent, on fait de même pour les fichiers suivants : conf/core-site.xml, conf/hdfs-site.xml, conf/mapred-site.xml.
IV-C-2. Mise à jour du fichier conf/core-site.xml▲
2.
3.
4.
5.
6.
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
Dans mon cas, pour faire exécuter mon programme, puisque mon utilisateur hadoop n'avait pas tous les droits sur mon répertoire /home/hadoop/hadoop/input, j'ai dû laisser la balise <value> ci-dessus vide pour que mon programme WordCount.jar puisse s'exécuter. J'en parlerai plus en détail dans les chapitres suivants notamment dans le chapitre Exécution d'un programme exemple : WordCount et dans le chapitre Les potentielles erreurs et comment les résoudre.
IV-C-3. Mise à jour du fichier conf/hdfs-site.xml▲
2.
3.
4.
5.
6.
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
IV-C-4. Mise à jour du fichier conf/mapred-site.xml▲
2.
3.
4.
5.
6.
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
Pour avancer, il faut vous assurer que vous pouvez accéder à votre machine virtuelle en faisant
ssh localhost
sans avoir besoin de mot de passe.
Si le mot de passe est demandé, vous devez exécuter les commandes suivantes pour la création d'une clé ssh afin de passer l'étape du mot de passe.


Dans mon cas, je n'ai pas eu besoin de faire ces deux commandes, peut-être ce problème de clé ssh avait au préalable été réglé par l'administrateur système de l'entreprise dans laquelle je travaillais.
IV-D. Quelques cas d'exécution▲
IV-D-1. Formatage du système de fichier HDFS mis en place▲
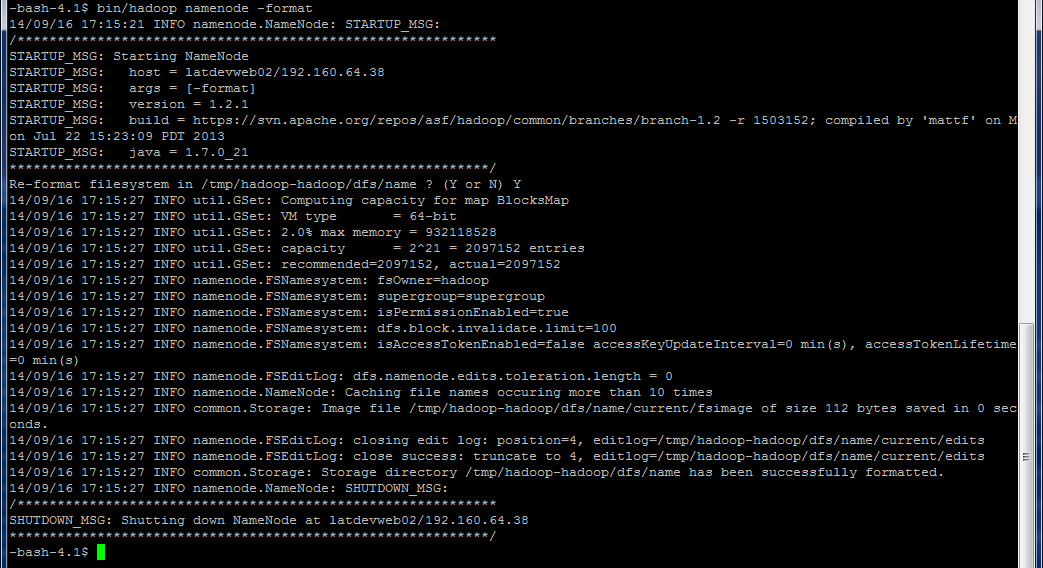
Avant d'utiliser notre cluster Hadoop pour la première fois, il est recommandé de formater le système de fichier HDFS Hadoop Distributed File Systemavant de démarrer les processus NameNode, SecondaryNameNode et DataNode. Pour lancer le formatage de notre HDFSHadoop Distributed File System, il faut faire la commande suivante :
bin/hadoop namenode -format.Vous devez avoir à l'issue de la commande une fenêtre ressemblant à la suivante :
IV-D-2. Lancement des jobs Hadoop▲
Pour démarrer tous les processus Hadoop à la fois, il suffit de faire la commande suivante :
bin/start-all.shLa fenêtre suivante illustre le démarrage de services Hadoop.

Il ne faut pas perdre de vue que vous pouvez démarrer chaque processus à son tour en utilisant une autre commande qui est la suivante pour chaque service:
/bin/hadoop-daemon.sh start xxxoù xxx représente namenode, secondarynamenode, datanode, jobtracker, tasktracker.
L'exécution des jobs Hadoop génère des fichiers de logs dans le répertoire /home/hadoop/hadoop/logs qui correspond au répertoire %HADOOP_HOME%/logs si la configuration est faite dans la variable d'environnement PATH.
IV-D-3. Aperçu des interfaces d'administration du cluster Hadoop▲
L'écran d'administration du système de fichiers est donné par la figure suivante : cette interface est accessible via le lien suivant :
NameNode -

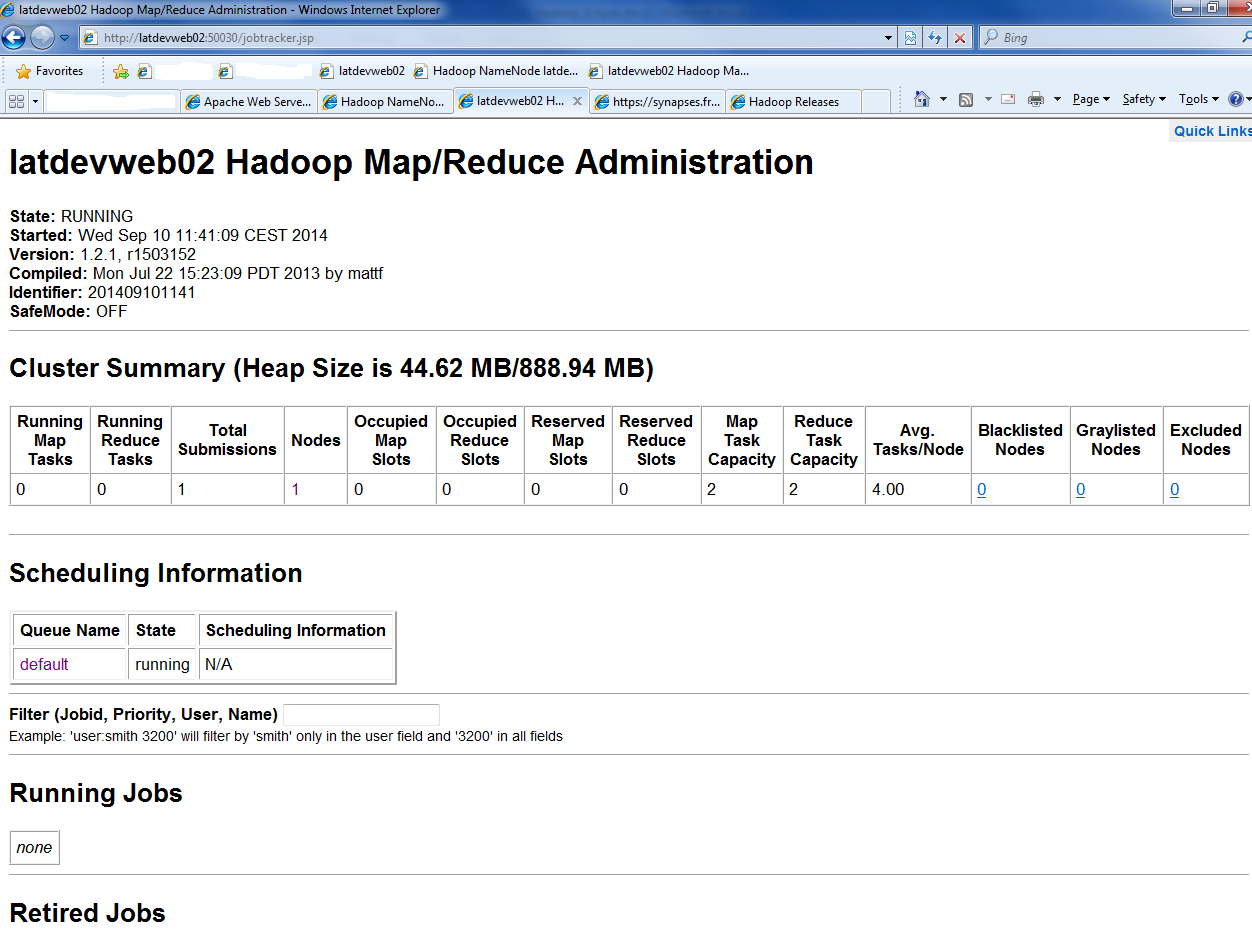
L'écran du gestionnaire de jobs MapReduce est donné par la figure suivante : cette interface est accessible par le lien suivant :
JobTracker -
IV-D-4. Arrêt des jobs Hadoop▲
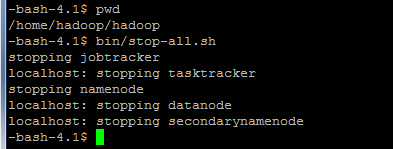
L'arrêt des jobs Hadoop est rendu possible par l'utilisation de la commande suivante :
bin/stop-all.shLe résultat est le suivant :
V. Configuration du lien entre Hadoop et Eclipse▲
Lorsqu'on a pris la folle habitude de développer en utilisant les IDEIntegrated Development Environment, il n'est pas toujours évident de se remettre à écrire des programmes en utilisant un simple éditeur de texte et compiler en ligne de commande.
Fondamentalement, l'écriture des programmes MapReduce devrait se faire « from scratch ». Cependant, les développeurs de la communauté ont pensé créer des plugins pour faciliter le développement des Jobs MapReduce en utilisant les IDE.
Nous allons voir dans ce chapitre comment intégrer le plugin Hadoop dans Eclipse et développer plus efficacement les jobs MapReduce.
V-A. Installation de Eclipse▲
Je ne reviens plus sur l'installation de Eclipse qui est supposée acquise. Peu importe la version de Eclipse que vous avez, cela devrait à priori fonctionner. Pour la réalisation de cet article, j'ai dû utiliser la version Europa, mais j'ai également testé la version Luna et tout fonctionne à merveille.
Allez sur le site de Eclipse, téléchargez la version qui vous intéresse, décompressez l'archive obtenue et le tour est joué.
Pas assez compliqué, l'installation de Eclipse.
V-B. Téléchargement et installation du plugin Hadoop pour Eclipse▲
Le plugin Hadoop pour Eclipse se présente comme une archive JAR. Plusieurs sites internet offrent un lien pour le téléchargement de ladite archive. J'ai pris le soin de vous en lister quelques-uns :
https://dl.dropboxusercontent.com/u/717667/hadoop/hadoop-eclipse-plugin-1.2.1.jar
http://crzyjcky.com/2013/09/03/hadoop-eclipse-plugin/hadoop-eclipse-plugin-1-2-1-jar/
http://ordinarygeek.me/2013/09/12/hadoop-build-and-install-hadoop-1-2-1-eclipse-plugin/
J'espère que vous avez bien remarqué qu'il s'agit du plugin pour la version 1.2.1 de Hadoop. Chaque distribution de Hadoop a à coup sûr une version de plugin correspondant ou du moins devrait.
Noter également qu'il est facile de s'en passer du plugin en utilisant Maven avec les dépendances Hadoop et MRUnitLibrairie pour test unitaire sous Hadoop. Malheureusement, dans le cadre de ce tutoriel, je n'ai pas expérimenté cette approche. Elle pourrait bien aider les uns et les autres à aller un peu plus loin dans cette aventure.
Téléchargez ce plugin et copiez-le dans un dossier de votre poste de travail.
V-C. Configuration du plugin Hadoop pour Eclipse▲
La configuration du plugin Hadoop pour Eclipse n'est pas plus difficile qu'un simple COPIER-COLLER. Ouvrez le dossier « plugin » de votre installation de Eclipse et y déposez-y l'archive du plugin. La capture d'écran suivante en illustre cette explication :
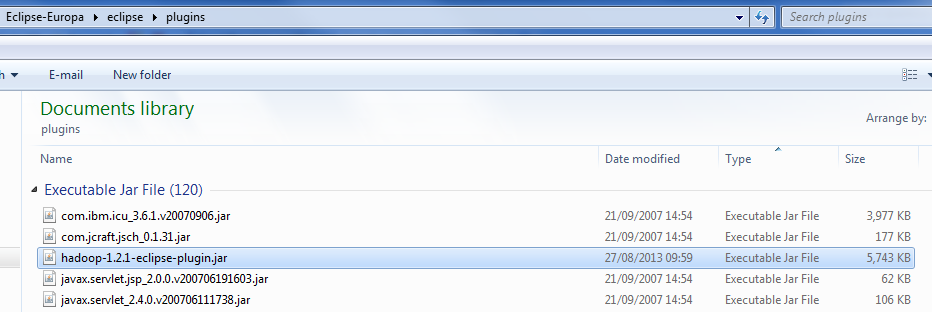
Remarquez bien, l'archive du plugin qui a été sélectionnée dans le dossier
« Eclipse-Europa/eclipse/plugins ». Ceci est une illustration de la situation sur mon poste de travail. Après avoir copié l'archive, renommez-la comme présenté dans la capture d'écran.
Enfin, redémarrez Eclipse.
Une fois que Eclipse a redémarré, vous devez voir apparaître dans le coin supérieur droit de Eclipse l'icône de l'éléphant violet comme le montre l'image suivante, preuve que le plugin a été pris en compte.
Désormais vous pouvez utiliser la perspective Hadoop pour écrire vos programmes MapReduce.
Cependant, la configuration n'est pas terminée. Nous devons renseigner Eclipse sur les paramètres de notre cluster qui est déjà fonctionnel.
Faites « Windows -> Show view ->MapReduce Locations», la fenêtre suivante apparaît:

Cliquez sur le petit éléphant violet pour configurer un nouveau cluster. La fenêtre suivante apparaît :

Cette fenêtre vous permet de saisir les paramètres de votre cluster. Vous avez deux onglets « Général » et « Advanced parameters ». Les informations que vous voyez là sont les informations propres à mon cluster. Vous devez renseigner les vôtres.
Désormais votre cluster est reconnu par Eclipse. Voir image suivante :

Vous avez ainsi la possibilité d'effectuer les opérations de base dans votre système de fichiers HDFS, créer, lister, renommer des répertoires, copier des fichiers, etc.
Dans l'onglet Project Explorer, vous pouvez voir un dossier en rapport avec mon cluster :
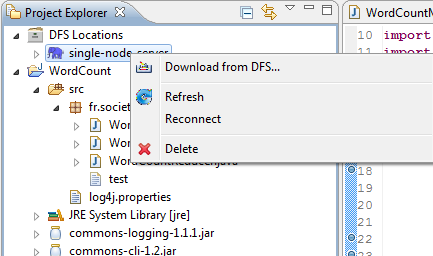
Le clic droit sur le cluster permet de faire plusieurs opérations dont nous n'allons pas détailler ici. À vous de découvrir.
V-D. Création d'un projet Hadoop sous Eclipse▲
Pour créer un projet, il faut faire
File -> New -> Project
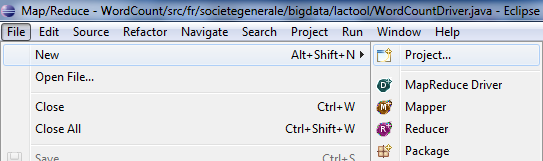
Ensuite, il faut sélectionner Map/Reduce Project et renseigner tous les paramètres, le nom du projet, etc.
Toutefois, vous pouvez créer un projet classique Java et ajouter à ce projet les classes Mapper, Reducer et MapReduce Driver. Ces classes représentent des spécificités de MapReduce et vous permettent également de créer des projets MapReduce.
Dans mon cas, c'est la deuxième option que j'ai utilisée pour la création de mon projet WordCount. Je l'ai trouvée plus maniable et plus proche du Java que je connais. Tout simplement parce que je ne suis pas un expert de Hadoop.
VI. Exécution d'un programme exemple: WordCount.jar▲
VI-A. Bibliothèques à importer dans le projet▲
Écrire un programme MapReduce en utilisant Eclipse se fait de la même façon qu'écrire un programme Java classique. On crée le projet, on crée éventuellement les packages qui contiendront les classes du projet et ensuite, on crée les classes telles que nous les avons décrites dans les paragraphes suivants.
Toutefois pour qu'un programme MapReduce puisse compiler proprement sous Eclipse, il faut attacher au projet un ensemble de bibliothèques et nous avons pris la peine de lister l'ensemble de ces bibliothèques pour éviter au lecteur de se perdre dans la recherche des bibliothèques. La figure suivante présente la liste des bibliothèques nécessaires.

Le dossier « lib » contient l'ensemble de ces fichiers jars. Ils ont été référencés dans le projet à partir de ce dossier. Il faut noter que le dossier est dans le projet que vous devrez créer.
VI-B. La classe WordCountMapper.java▲
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
package fr.yimson.bigdata.lactool;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class WordCountMapper extends MapReduceBase implements
Mapper<LongWritable, Text, Text, IntWritable> {
private final IntWritable one = new IntWritable(1);
private Text word = new Text();
//La classe de Map
@Override
public void map(LongWritable key, Text value,
OutputCollector<Text, IntWritable> output, Reporter reporter)
throws IOException {
// TODO Auto-generated method stub
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line.toLowerCase());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
VI-C. La classe WordCountReducer.java▲
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
package fr.yimson.bigdata.lactool;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
public class WordCountReducer extends MapReduceBase implements
Reducer<Text, IntWritable, Text, IntWritable> {
//La methode de Reduce
@Override
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()){
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
VI-D. La classe WordCountDriver.java▲
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
package fr.yimson.bigdata.lactool;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
public class WordCountDriver {
public static void main(String[] args) {
Configuration config = new Configuration();
// config.set("fs.default.name", "hdfs://latdevweb02:9000/");
// config.set("mapred.job.tracker", "latdevweb02:9001");
JobClient client = new JobClient();
JobConf conf = new JobConf(config);
// TODO: specify output types and set jar
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setJar("WordCount.jar");
// TODO: specify a mapper and a reducer and the combiner
conf.setMapperClass(fr.yimson.bigdata.lactool.WordCountMapper.class);
conf.setCombinerClass(fr.yimson.bigdata.lactool.WordCountReducer.class);
conf.setReducerClass(fr.yimson.bigdata.lactool.WordCountReducer.class);
// TODO: specify input and output DIRECTORIES (not files)
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
// TODO: specify input and output DIRECTORIES (not files)
FileInputFormat.setInputPaths(conf, new Path(
"/home/hadoop/hadoop/input"));
FileOutputFormat.setOutputPath(conf, new Path(
"/home/hadoop/hadoop/output"));
System.out.println("Entrée dans le programme MAIN !!!");
client.setConf(conf);
try {
JobClient.runJob(conf);
System.out.println("Sortie du programme MAIN!!!");
} catch (Exception e) {
e.printStackTrace();
}
}
}
VI-E. Résultats de l'exécution du programme▲
Le résultat que vous voyez ci-dessous ne s'est pas obtenu d'un seul coup. J'ai débogué ce programme au point de me demander si je savais encore développer en Java. Après moult essais, je me suis rendu compte qu'il ne s'agit nullement de compétence en développement Java, mais qu'il s'agit de compréhension de l'environnement Hadoop. Hadoop est un framework et son rôle primordial est de faciliter la tâche du développeur.
Objectivement, je n'exprime ici que le fond de ma pensée et le ressenti que j'ai eu après cette expérience. J'ai eu l'impression d'une sorte de deux poids deux mesures. Soit l'écosystème Hadoop n'est pas encore assez mature pour permettre une mise en œuvre aisée, soit je n'ai pas encore la maturité nécessaire pour comprendre cet environnement. Toutefois comme je le dis, chacun pourrait avoir son point de vue différent du mien. Ne nous égarons pas.
Voici la sortie du résultat de l'exécution de mon programme.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
54.
55.
56.
57.
58.
59.
60.
-bash-4.1$ bin/hadoop jar WordCount.jar
Entr?e dans le programme MAIN !!!
14/09/15 15:00:41 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the sam.
14/09/15 15:00:41 INFO util.NativeCodeLoader: Loaded the native-hadoop library
14/09/15 15:00:41 WARN snappy.LoadSnappy: Snappy native library not loaded
14/09/15 15:00:41 INFO mapred.FileInputFormat: Total input paths to process : 17
14/09/15 15:00:42 INFO mapred.JobClient: Running job: job_201409101141_0008
14/09/15 15:00:43 INFO mapred.JobClient: map 0% reduce 0%
14/09/15 15:00:50 INFO mapred.JobClient: map 11% reduce 0%
14/09/15 15:00:53 INFO mapred.JobClient: map 17% reduce 0%
14/09/15 15:00:54 INFO mapred.JobClient: map 23% reduce 0%
14/09/15 15:00:56 INFO mapred.JobClient: map 35% reduce 0%
14/09/15 15:00:59 INFO mapred.JobClient: map 47% reduce 0%
14/09/15 15:01:02 INFO mapred.JobClient: map 58% reduce 0%
14/09/15 15:01:04 INFO mapred.JobClient: map 64% reduce 0%
14/09/15 15:01:05 INFO mapred.JobClient: map 70% reduce 19%
14/09/15 15:01:07 INFO mapred.JobClient: map 82% reduce 19%
14/09/15 15:01:09 INFO mapred.JobClient: map 88% reduce 19%
14/09/15 15:01:10 INFO mapred.JobClient: map 94% reduce 19%
14/09/15 15:01:11 INFO mapred.JobClient: map 100% reduce 19%
14/09/15 15:01:14 INFO mapred.JobClient: map 100% reduce 27%
14/09/15 15:01:15 INFO mapred.JobClient: map 100% reduce 100%
14/09/15 15:01:16 INFO mapred.JobClient: Job complete: job_201409101141_0008
14/09/15 15:01:16 INFO mapred.JobClient: Counters: 29
14/09/15 15:01:16 INFO mapred.JobClient: Job Counters
14/09/15 15:01:16 INFO mapred.JobClient: Launched reduce tasks=1
14/09/15 15:01:16 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=47158
14/09/15 15:01:16 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
14/09/15 15:01:16 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
14/09/15 15:01:16 INFO mapred.JobClient: Rack-local map tasks=17
14/09/15 15:01:16 INFO mapred.JobClient: Launched map tasks=17
14/09/15 15:01:16 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=25510
14/09/15 15:01:16 INFO mapred.JobClient: File Input Format Counters
14/09/15 15:01:16 INFO mapred.JobClient: Bytes Read=34293
14/09/15 15:01:16 INFO mapred.JobClient: File Output Format Counters
14/09/15 15:01:16 INFO mapred.JobClient: Bytes Written=16014
14/09/15 15:01:16 INFO mapred.JobClient: FileSystemCounters
14/09/15 15:01:16 INFO mapred.JobClient: FILE_BYTES_READ=65480
14/09/15 15:01:16 INFO mapred.JobClient: HDFS_BYTES_READ=1715
14/09/15 15:01:16 INFO mapred.JobClient: FILE_BYTES_WRITTEN=1080096
14/09/15 15:01:16 INFO mapred.JobClient: Map-Reduce Framework
14/09/15 15:01:16 INFO mapred.JobClient: Map output materialized bytes=31283
14/09/15 15:01:16 INFO mapred.JobClient: Map input records=956
14/09/15 15:01:16 INFO mapred.JobClient: Reduce shuffle bytes=31283
14/09/15 15:01:16 INFO mapred.JobClient: Spilled Records=3154
14/09/15 15:01:16 INFO mapred.JobClient: Map output bytes=46384
14/09/15 15:01:16 INFO mapred.JobClient: Total committed heap usage (bytes)=2796748800
14/09/15 15:01:16 INFO mapred.JobClient: CPU time spent (ms)=7520
14/09/15 15:01:16 INFO mapred.JobClient: Map input bytes=34293
14/09/15 15:01:16 INFO mapred.JobClient: SPLIT_RAW_BYTES=1715
14/09/15 15:01:16 INFO mapred.JobClient: Combine input records=3435
14/09/15 15:01:16 INFO mapred.JobClient: Reduce input records=1577
14/09/15 15:01:16 INFO mapred.JobClient: Reduce input groups=820
14/09/15 15:01:16 INFO mapred.JobClient: Combine output records=1577
14/09/15 15:01:16 INFO mapred.JobClient: Physical memory (bytes) snapshot=3333201920
14/09/15 15:01:16 INFO mapred.JobClient: Reduce output records=820
14/09/15 15:01:16 INFO mapred.JobClient: Virtual memory (bytes) snapshot=11883048960
14/09/15 15:01:16 INFO mapred.JobClient: Map output records=3435
Sortie du programme MAIN !!!
-bash-4.1$ bin/hadoop jar WordCount.jar
VII. Les potentielles erreurs et comment les résoudre▲
VII-A. Arrêt inopiné du processus DataNode▲
Le débogage d'un programme MapReduce suit les mêmes règles que vous avez toujours appliquées pour le débogage d'autres programmes. Vous avez toujours la possibilité d'insérer des points d'arrêt dans le programme, d'utiliser les instructions d'impression à l'écran et même la bibliothèque log4j, etc.
Cependant, il y a des erreurs qui apparaissent et qui ne peuvent toujours pas être détectées avec ces méthodes classiques. Nous présentons dans ce paragraphe une erreur qui arrive très souvent lorsqu'on simule un cluster Hadoop en mode pseudodistribué. Il s'agit de l'arrêt inopiné du processus DataNode. Ceci signifie purement et simplement que votre système de fichier HDFSHadoop Distributed File System n'est plus accessible.
Pour reconnaitre cette erreur, le message suivant peut apparaître lors de l'exécution d'un programme MapReduce :
- il y a plusieurs tentatives de connexions au système de fichier HDFSHadoop Distributed File System qui se matérialisent par des messages tels qu'illustrés par la capture d'écran suivante :

- après plusieurs tentatives de connexions (par défaut 10), le message d'erreur
Exception in thread “main” java.lang.RuntimeException: java.net.ConnectException: Call to localhost/127.0.0.1:9000 failed on connection option: java.net.ConnectException: Connection refused

- pour se rendre bien compte de cela, il faut se positionner dans le répertoire d'installation de Hadoop et faire la commande suivante :
jpsCette commande liste l'ensemble des processus Hadoop qui sont fonctionnels au moment où la commande est lancée. Une illustration est donnée par la capture d'écran suivante :
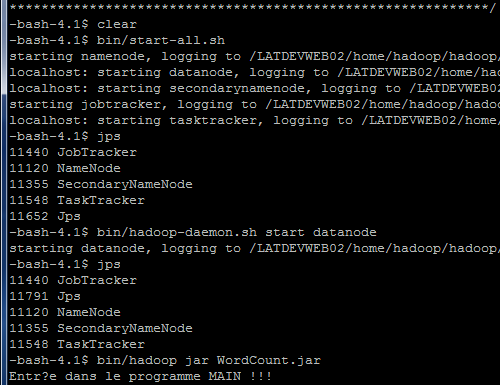
Pour résoudre le problème, il faut faire les actions suivantes dans l'ordre défini ci-dessous :
- il faut tout d'abord arrêter tous les processus Hadoop qui sont démarrés actuellement. Nous avons montré au chapitre 2 de ce tutoriel comment arrêter les processus Hadoop ;
- dans le cluster, il faut identifier le datanode qui pose problème, puisque nous sommes en mode pseudodistribué, le datanode c'est notre machine virtuelle. Le cluster entier est simulé sur notre machine virtuelle et tous les processus Hadoop tournent dessus. Une fois le datanode identifié, il faut supprimer le dossier DATA dans lequel Hadoop stocke les fichiers issus de l'exécution des programmes. Dans notre cas, il s'agit du répertoire /home/hadoop/hadoop/tmp/dfs/data/ ;
- il faut par la suite lancer la commande de formatage du cluster. Nous avons dans le chapitre 2 expliqué comment procéder ;
- enfin, il faut redémarrer les processus Hadoop comme présenté dans le chapitre 2.
Toutes ces opérations concourent à réinitialiser proprement le cluster. Après cela, il faut refaire la commande JPS, pour vous assurer que tout est rentré dans l'ordre.
VII-B. Pas de permissions accordées pour accéder au cluster▲
Cette erreur arrive lorsque l'utilisateur avec lequel vous lancez le programme MapReduce n'a pas suffisamment de droits pour écrire dans les répertoires du cluster Hadoop. Je vais expliquer le cas auquel j'ai été confronté.
En effet, le poste de travail sur lequel, j'avais installé tout mon environnement de développement était une machine Windows 7. Tout y était installé notamment Eclipse, plugin Hadoop, etc. Ma machine virtuelle était une machine RedHat comme présenté au départ. Dans mes premiers essais, je lançais l'exécution de mon programme MapReduce directement à partir de Eclipse, et j'ai fait face pendant plusieurs jours à l'erreur suivante :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
50.
51.
52.
53.
2014-09-04 14:00:55,050 ERROR [org.apache.hadoop.security.UserGroupInformation] - PriviledgedActionException as:gyimenyi041514 cause:org.apache.hadoop.security.AccessControlException: org.apache.hadoop.security.AccessControlException: Permission denied: user=gyimenyi041514, access=WRITE, inode="staging":hadoop:supergroup:rwxr-xr-x
org.apache.hadoop.security.AccessControlException: org.apache.hadoop.security.AccessControlException: Permission denied: user=gyimenyi041514, access=WRITE, inode="staging":hadoop:supergroup:rwxr-xr-x
at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
at sun.reflect.NativeConstructorAccessorImpl.newInstance(Unknown Source)
at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(Unknown Source)
at java.lang.reflect.Constructor.newInstance(Unknown Source)
at org.apache.hadoop.ipc.RemoteException.instantiateException(RemoteException.java:95)
at org.apache.hadoop.ipc.RemoteException.unwrapRemoteException(RemoteException.java:57)
at org.apache.hadoop.hdfs.DFSClient.mkdirs(DFSClient.java:1459)
at org.apache.hadoop.hdfs.DistributedFileSystem.mkdirs(DistributedFileSystem.java:362)
at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:126)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:942)
at org.apache.hadoop.mapred.JobClient$2.run(JobClient.java:936)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Unknown Source)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:936)
at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:910)
at org.apache.hadoop.mapred.JobClient.runJob(JobClient.java:1353)
at fr.societegenerale.bigdata.lactool.WordCountDriver.main(WordCountDriver.java:51)
Caused by: org.apache.hadoop.ipc.RemoteException: org.apache.hadoop.security.AccessControlException: Permission denied: user=gyimenyi041514, access=WRITE, inode="mapred":hadoop:supergroup:rwxr-xr-x
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:217)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:197)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkPermission(FSPermissionChecker.java:141)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkPermission(FSNamesystem.java:5758)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.checkAncestorAccess(FSNamesystem.java:5731)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirsInternal(FSNamesystem.java:2502)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.mkdirs(FSNamesystem.java:2469)
at org.apache.hadoop.hdfs.server.namenode.NameNode.mkdirs(NameNode.java:911)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:601)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:587)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1432)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1428)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1190)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:1426)
at org.apache.hadoop.ipc.Client.call(Client.java:1113)
at org.apache.hadoop.ipc.RPC$Invoker.invoke(RPC.java:229)
at com.sun.proxy.$Proxy1.mkdirs(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(Unknown Source)
at java.lang.reflect.Method.invoke(Unknown Source)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:85)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:62)
at com.sun.proxy.$Proxy1.mkdirs(Unknown Source)
at org.apache.hadoop.hdfs.DFSClient.mkdirs(DFSClient.java:1457)
... 11 more
Après quelques jours de réflexion, je suis arrivé à la compréhension suivante de la situation que j'explique ici.
Après plusieurs recherches sur des forums, j'ai compris qu'à partir de mon poste de travail, je suis connecté en tant que « gyimenyi041514 », et cet utilisateur n'avait aucune permission pour exécuter des jobs Hadoop sur la machine virtuelle RedHat.
L'autre problème est que le job MapReduce que je lançais à partir de Eclipse essayait de créer un dossier dans le répertoire nommé « staging » en utilisant mon username Windows « gyimenyi041514 ». Voir dans le message d'erreur précédent. Cependant, le dossier « staging » appartient à l'utilisateur « hadoop ». Ainsi, les actions de l'utilisateur « gyimenyi041514 » ne pouvaient qu'échouer.
Dans mon cas, pour remédier à cette situation, désormais pour tester mon programme, j'exportais mon programme sous forme d'un fichier Jar, que je déposais dans le dossier d'installation de Hadoop et que je pouvais lancer cette fois en utilisant la commande suivante :
-bash-4.1$ bin/hadoop jar WordCount.jarDésormais, je pouvais tout faire avec l'utilisateur « hadoop » qui possède tous les droits. Facile n'est-ce pas, mais pas évident à voir. Je vous assure.
J'avais un enseignant qui disait, je le cite : « Mes chers enfants, qu'est-ce que l'informatique ? L'informatique c'est du bricolage … » et c'était très marrant. Je confirme cela aujourd'hui face à certaines situations. N'oublions pas notre objectif.
Je viens de présenter ici, les erreurs qui m'ont le plus tracassé. Il y en a eu d'autres, mais qui sont des erreurs classiques lorsqu'on exécute un programme Java en ligne de commande. Je fais allusion aux erreurs en rapport avec le fichier MANIFEST, en rapport avec la configuration du CLASSPATH, etc.
VII-C. L'erreur INPUT PATH does not exist▲
Une autre erreur susceptible d'arriver aux débutants dans l'écosystème Hadoop est l'erreur INPUT PATH DOES NOT EXIST. Nous présentons ci-dessous son contexte et comment y faire face. Comme toujours depuis le début de ce tutoriel, il s'agit de mon expérience, j'explique ce que j'ai fait pour y faire face. Je rappelle que je ne suis pas un expert, je m'intéresse et je me documente sur cet univers.
2.
3.
4.
5.
6.
7.
8.
9.
-bash-4.1$ bin/hadoop jar WordCount.jar
Entr?e dans le programme MAIN !!!
14/09/11 12:06:10 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
14/09/11 12:06:10 INFO util.NativeCodeLoader: Loaded the native-hadoop library
14/09/11 12:06:10 WARN snappy.LoadSnappy: Snappy native library not loaded
14/09/11 12:06:10 INFO mapred.JobClient: Cleaning up the staging area hdfs://latdevweb02:9000/user/hadoop/.staging/job_201409101141_0005
14/09/11 12:06:10 ERROR security.UserGroupInformation: PriviledgedActionException as:hadoop cause:org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://latdevweb02:9000/home/hadoop/hadoop/input
org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://latdevweb02:9000/home/hadoop/hadoop/input
at org.apache.hadoop.mapred.FileInputFormat.listStatus(FileInputFormat.java:197)
En effet, lorsqu'un programme MapReduce s'exécute, il lit des fichiers qui se trouvent dans un répertoire précis qui a été soit mentionné dans la configuration du fichier core/hdfs-site.xml, soit dans le programme proprement dit.
Ce qu'il faut noter est que lorsque ladite configuration est faite dans le programme directement, c'est celle-là qui est prioritaire. Pour résoudre le problème, et pouvoir exécuter le programme, j'ai dû supprimer la configuration que j'avais faite dans la balise <value> pour la propriété «fs.default.name » dans le fichier core/hdfs-site.xml.
Les leçons que je retiens de cette erreur sont que lorsque vous exécutez un programme Hadoop, vous devez vous assurer que les fondamentaux suivants sont garantis :
- premièrement, le dossier OUTPUT (où les résultats doivent être stockés) ne doit pas exister, car il sera créé par le programme. Sauf si, vous l'avez défini explicitement dans le fichier conf/hdfs-site.xml ;
- deuxièmement, si vous avez défini le dossier INPUT en utilisant l'instruction suivante dans votre programme :
FileInputFormat.setInputPaths(conf, new Path("/home/hadoop/hadoop/input"));vous devez laisser vide la balise <value> de la propriété «fs.default.name » dans le fichier core/hdfs-site.xml.
VIII. Références▲
Pour réaliser cet article, je me suis inspiré de plusieurs articles et blogs en ligne. Je ne suis pas un expert de l'écosystème Hadoop. Toutefois, je m'intéresse et me documente sur le sujet. Cet article est le résultat d'une capitalisation des retours d'expérience çà et là. Je vais énumérer quelques liens, cependant, il faudra bien garder à l'esprit que la liste n'est pas exhaustive.
https://developer.yahoo.com/hadoop/tutorial/module7.html
http://www.michael-noll.com/tutorials/
http://hadoop.apache.org/docs/r1.2.1/single_node_setup.html
http://ordinarygeek.me/2013/09/12/hadoop-build-and-install-hadoop-1-2-1-eclipse-plugin/
http://crzyjcky.com/2013/09/03/hadoop-eclipse-plugin/hadoop-eclipse-plugin-1-2-1-jar/
http://solaimurugan.blogspot.fr/2014/04/configuring-eclipse-for-apache-hadoop.html
http://glebche.appspot.com/static/hadoop-ecosystem/mapreduce-job-java.html
http://stackoverflow.com/questions/17507670/basic-permissions-error-in-mr2
http://www.codeweblog.com/hadoop-study-notes-five-use-of-eclipse-plug-in/
http://pcbje.com/2012/08/submitting-hadoop-mapreduce-jobs-to-a-remote-jobtracker/
http://stackoverflow.com/questions/20315862/hadoop-jar-jobtracker-is-in-safe-mode
IX. Remerciements▲
Je remercie particulièrement ces blogueurs et ces passionnés de la technologie Hadoop. Je remercie Mickael Baron pour ses conseils d'expert et pour sa relecture technique, sans oublier ClaudeLELOUP pour sa relecture orthographique. Leurs apports respectifs m'ont permis de produire cet article. Les brillants lecteurs de la communauté www.developpez.com et bien entendu tous ceux qui de près ou de loin m'ont aidé dans la production de ce travail.